事業開発顧問/マーケティングコンサルタント 中嶋 正生【文責】
【マーケッターによるマーケティング・ダッシュボードPoC日記-2】
⇒マーケッターによるマーケティング・ダッシュボードPoC日記-1
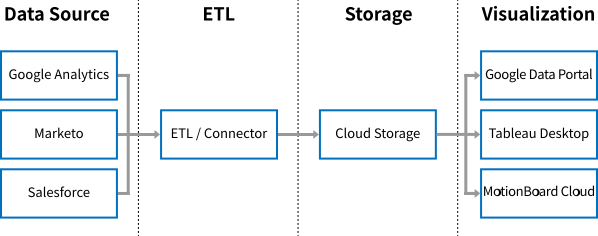
Marketo、Salesforce、Google Analyticsのデータを1つのダッシュボードで可視化したい
PoCの計画を立て、次に検証に入ります。ETLとクラウドストレージを選定し、分析用データマートを構築します。 ETLの選定に関しては、CData Syncにすんなり決まったのですが、どのクラウドストレージにデータを蓄積すべきか思いのほか、選定には時間がかかりました。紆余曲折を経て、最終的にはGoogle BigQueryを選定しました。
【図2-1】実現したいデータ取得/蓄積/可視化のしくみ
※関連ナレッジ資料※
マーケティング成果に直結させるGA4分析のポイント をダウンロード
サービス名:CData Sync
URL:http://www.cdata.com/jp/sync
CData Syncは、SaaSとして提供されているクラウドサービスのデータを取得することができます。今回の検証で取得したいデータソースである、Google Analytics, Marketo, Salesforceはもちろんのこと、100種類以上のデータソースに対応しています。複数のデータソースから、スナップショット(ある時点のデータの断面)を作成することができます。これにより過去データとの比較や時系列の推移などを簡単に把握することが可能になります。また、データを取得する際、差分のみの更新が可能なので、クラウドストレージへのデータ転送量を抑えることができ、データ転送に要する時間も短縮することができます。操作も非常に簡単で、直観的な管理コンソールが提供されており、ノンコーディングでデータの取得ができます。スケジューリング機能も搭載されており、日次バッチにも容易に対応することができるので、運用時の負荷を極力抑えることができるのが運用担当者には嬉しい機能です。
【図2-2】CData Syncのクラウド/SaaS データソース ラインアップの一部
CData Syncの同期先として対応しているクラウドストレージ(Amazon RedShift, Amazon S3, Google BigQuery, Google Cloud SQL, etc.)を候補とし、インフラエンジニアの意見も参考に吟味した結果、Google BigQueryを選定しました。
【図2-3】
| クラウドストレージ | カテゴリ | 評価 |
|---|---|---|
| Amazon RedShift | DMP | 課金体系が起動時間(ストレージの利用容量と保存している期間)をベースとしているので、データを使っても使わなくても一定の金額が毎月かかってしまう。結果として運用コストが高い。 |
| Amazon S3 | Storage | ストレージ専用で低価格なのが魅力的だが、パフォーマンスが悪く非常に遅い。 |
| Google BigQuery | DMP | BigQueryに格納されるデータの量と各クエリで処理されるデータの量に基づいて課金されるので、随時大量のクエリが投げられるような利用方法ではない場合、圧倒的にコストパフォーマンスが良い。 |
| Google Cloud SQL | Database | 利用データが正規化データでリレーショナルを重視するのであれば良いが、ログのような非正規データを大量に扱うのは不向き。 |
| Google Spread Sheet | Spread Sheet | 無償で利用できるのが最大のメリットだが、500万セルという制限がボトルネックで運用に耐えられない。 |
●導入自体はGoogleアカウントにクレジットカード情報を紐づけるだけで、非常に簡単である。
●無償トライアル版の登録をすると約$300分の利用可能クレジットが無償で付帯される。
●実行するクエリの容量(費用)を事前に試算することが出来るため、過って大きなクエリを発行することを防ぐことが出来る。
●データを別サービスから取り込み、テーブルが出来るまでには最大90分かかる場合がある。
●取り込み日やID別のパーティションニングの設定が可能である。
尚、クエリ発行時の注意点として、BigQueryはカラム型のデータ構造を持っているため、カラムを省略したSelect文(Select * from ~)のクエリを発行すると対象のデータの全件が抽出対象となります。この場合、LIMITおよびWhere句で絞り込んでも全件参照されます。不要なクエリ発行コストを抑えるために、抽出する項目を指定し、LIMITやWhere句で抽出対象のデータの件数を絞り込むなどの工夫が必要となります。
全体のコスト、パフォーマンス、運用負荷、etc.を考慮するとETLおよびクラウドストレージの選定は極めて重要です。今回、データソースとして、Google Analytics, Marketo および Salesforceのデータ取得が絶対条件であり、これらのデータソースに対応しているETLを選定し、そこからETLが同期先として対応しているクラウドストレージを選択しました。
最初にどのデータソースからデータ取得したいかを明確にし、さらに、取得したいデータソースが増えた場合にも柔軟に対応できるETLを選択するのが得策です。また、クラウドストレージには、それぞれ特徴があるので、蓄積したいデータの種類によってクラウドストレージを選定するのがよいと思います。もちろん、費用や運用時の負荷も含めて考慮する必要があります。
それでは実際に、CData Syncを使って、3つのデータソース(Google Analytics, Marketo, Salesforce)から、Google BigQueryにデータを蓄積する手順について詳しく解説します。
データの取得元のサービスを選択し、接続設定を行います。
●Marketo
●Salesforce
●Google Analytics

データ書き込み先のサービス・DB等を選択し、接続設定を行います。
●Google BigQuery
●Google Cloud SQL(MySQL)

上記で選択したデータソースから同期先へのレプリケート(複製)設定を行います。
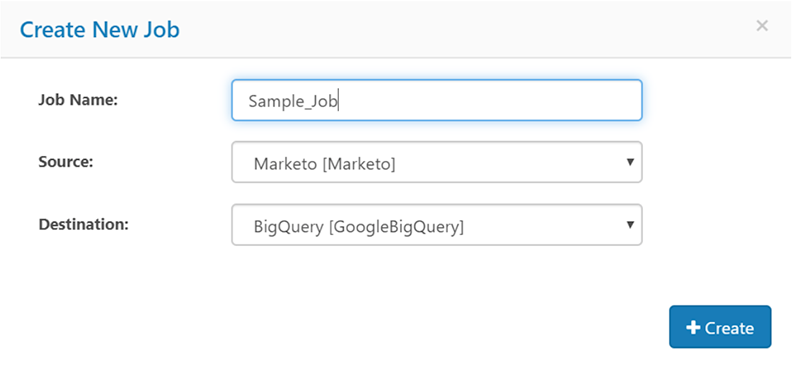
3-1.ジョブを作成し、データソースと同期先を設定します。ここではMarketoのデータをBigQueryにレプリケートしています。
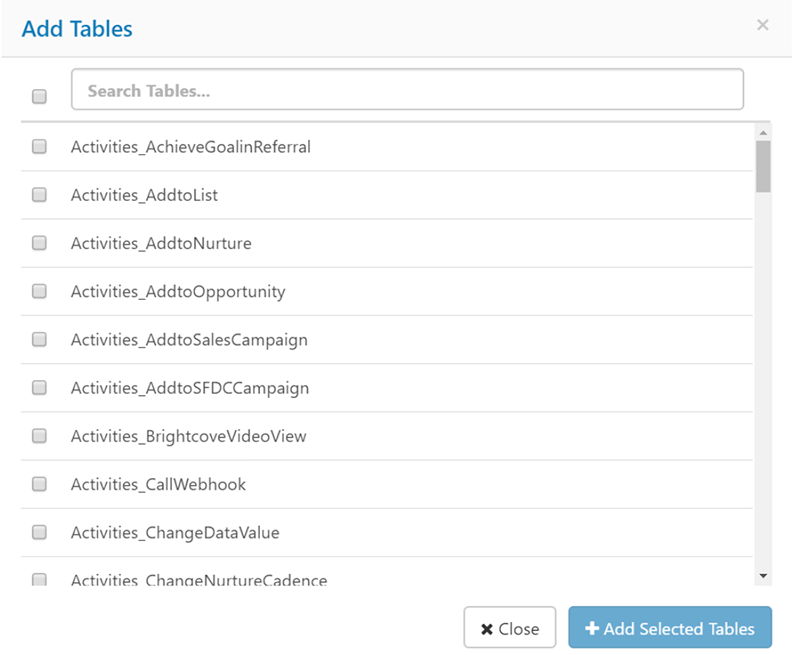
3-2. データソースからレプリケート対象のテーブルを選択します。 Marketoのアクティビティログは下図のように複数のテーブルに分かれています。
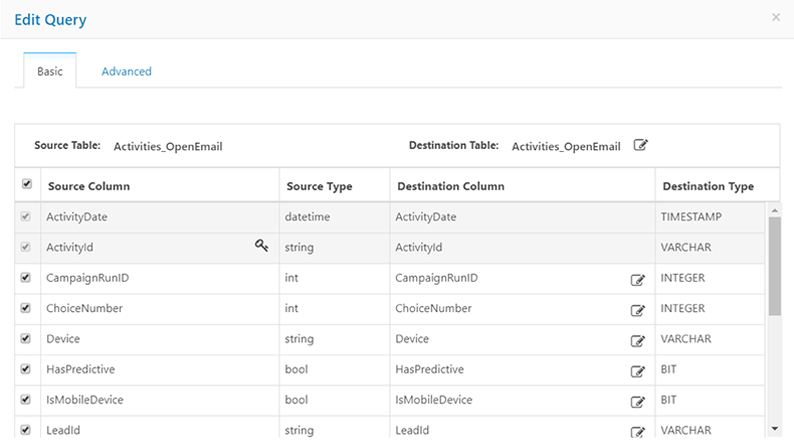
3-3.対象のテーブルから連携対象の項目を選択します。Marketoの「メール開封」のアクティビティはこのようなフィールドで構成されています。
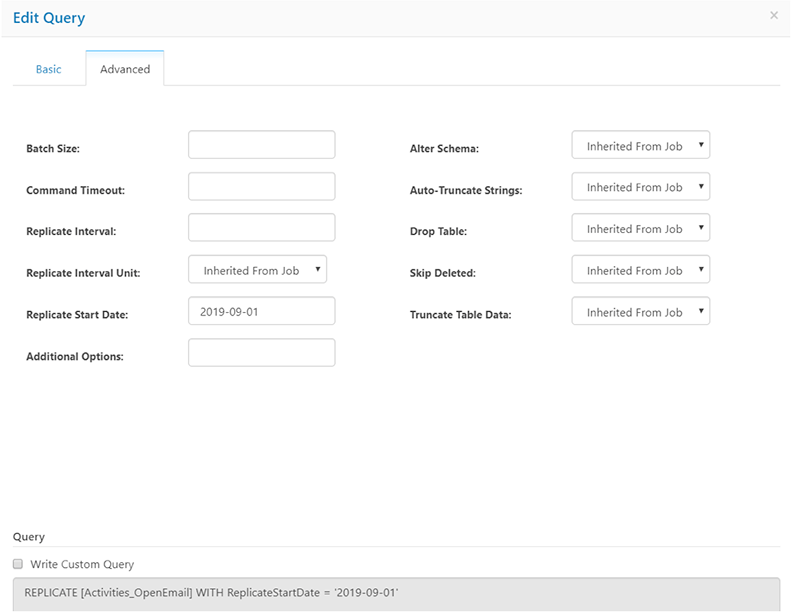
3-4. レプリケートするデータの期間等の設定を行います。
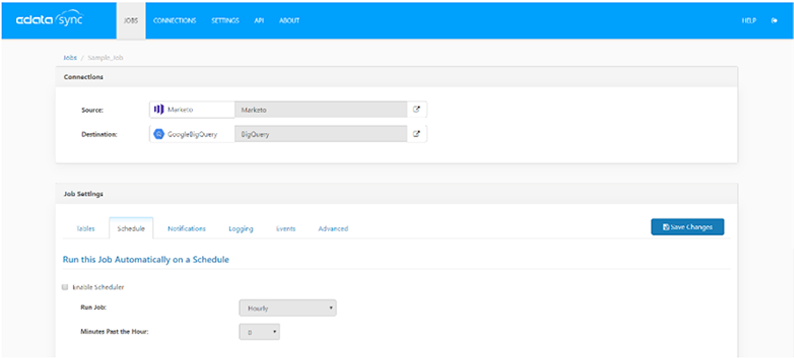
3-5. ジョブのスケジューリングを行います。
以上で、設定は終了です。実際に操作をしてみた感想を簡単にまとめてみました。
●シンプルなUIで、未経験者でも実際のデータ連携設定が可能
●カスタムでSQLを直接書けるなど、拡張性もあり複雑なニーズにも対応可能
●差分データや全データの取得が可能
少し機能を補足しますと、スケジューリング機能を使えば、日次バッチが実現できます。毎日同じ時刻に、全データを履歴としてすべて取得するのか、差分データのみ更新するのか、選択することもできるので、用途に応じて設定する必要があります。
尚、Google Analyticsからのデータ連携に関しては、対象のビューごとに個別にSQLを書く必要があるので、ジョブの設定方法がやや異なります。
ライセンスに関してですが、CData Sync を利用する場合、利用したいデータソース(Marketo, Salesforce, Google Analytics)によってライセンスのタイプが異なります。また、データソースから取得したデータを格納する場合も同様で、利用したい同期先によってライセンスのタイプが異なりますので注意が必要です。
⇒マーケッターによるマーケティング・ダッシュボードPoC日記-3
実際にダッシュボードを作る過程で見えてきた、ツールごとの特性

中嶋 正生

2023.03.27

2023.03.22

2023.01.20